Chapter 9 First Ticket
After completing the previous chapters, your supervisor will assign a ticket from RT. Login using your LDAP credentials got get familiarized with RT.
9.1 Navigate RT
The RT ticketing system is how we
communicate with folks interacting with the Arctic Data Center.
We use it for managing submissions, accessing issues, etc. It consists of
three separate interfaces:
Front Page
All Tickets
Ticket Page
9.1.1 Front page
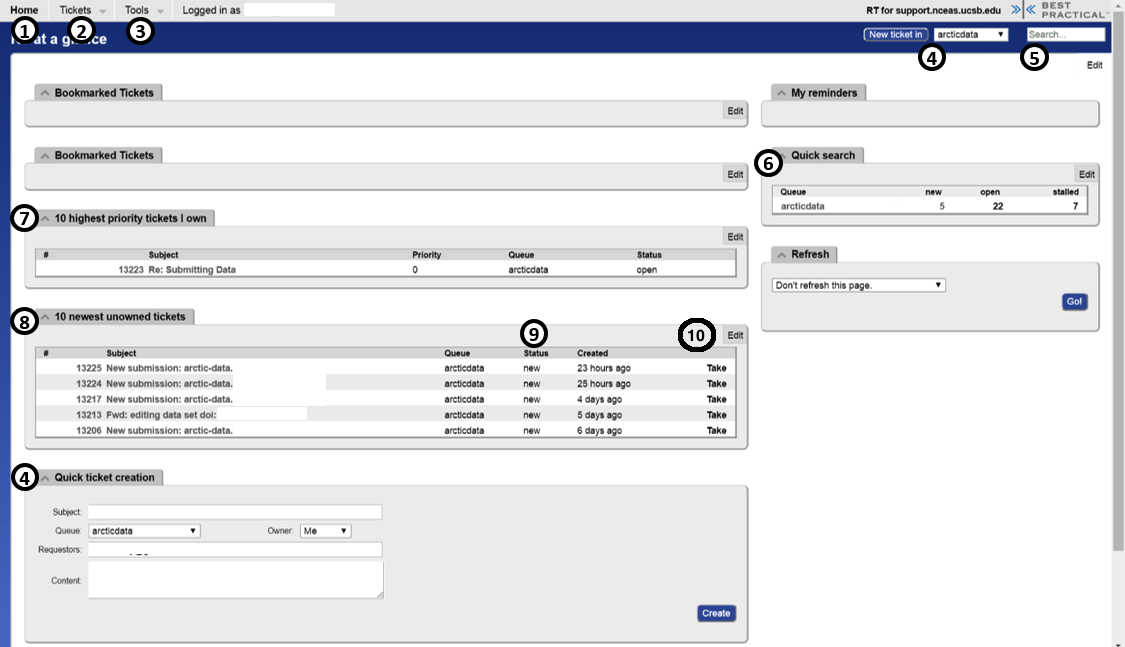
This is what you see first
- Home - brings you to this homepage
- Tickets - to search for tickets (also see number 5)
- Tools - not needed
- New Ticket - create a new ticket
- Search - Type in the ticket number to quickly navigate to a ticket
- Queue - Lists all of the tickets currently in a particular queue (such as ‘arcticdata’) and their statuses
- New = unopened tickets that require attention
- Open = tickets currently open and under investigation and/or being processed by a support team member
- Stalled = tickets awaiting responses from the PI/
submitter
- Tickets I Own - These are the current open tickets that are claimed by me
- Unowned Tickets - Newest tickets awaiting claim
- Ticket Status - Status and how long ago it was created
- Take - claim the ticket as yours
9.1.2 All tickets

This is the queue interface from number 6 of the Front page
1. Ticket number and title
2. Ticket status
3. Owner - who has claimed the ticket
9.1.3 Example ticket
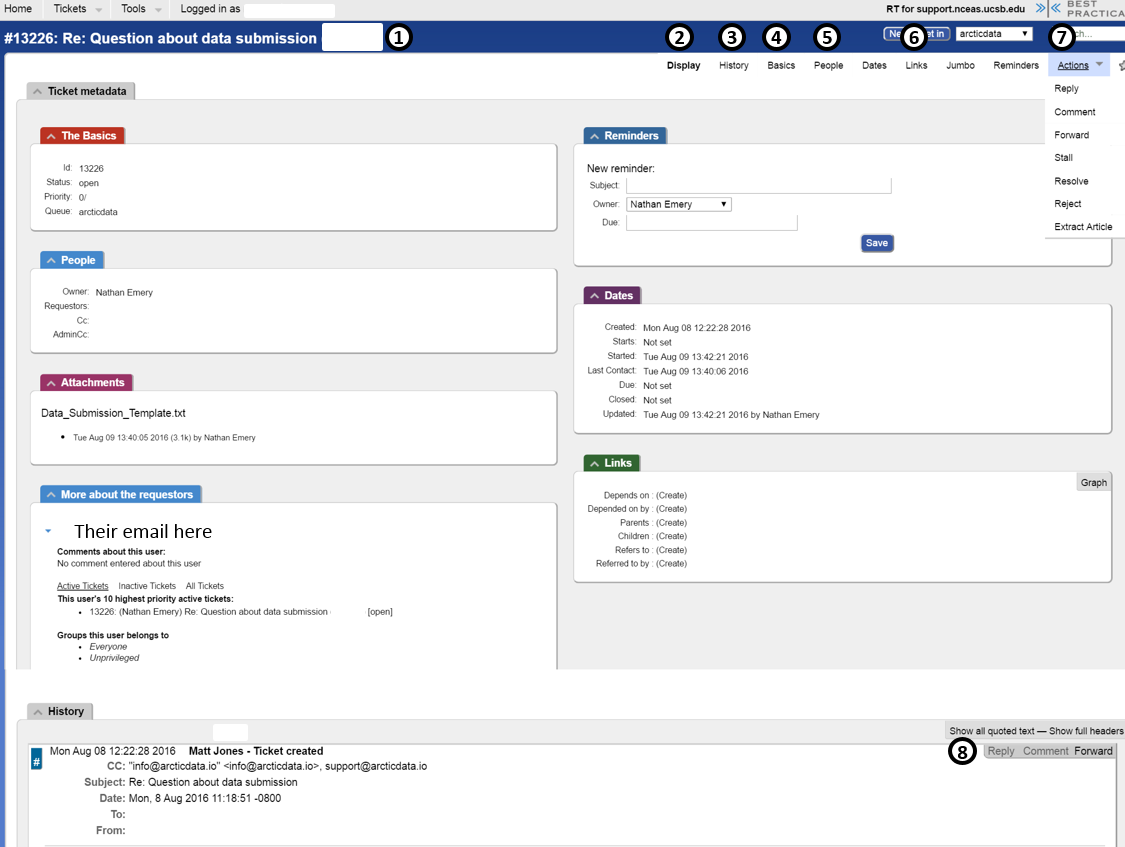
- Title - Include the PI’s name for reference
- Display - homepage of the ticket
- History - Comment/Email history, see bottom of Display page
- Basics - edit the title, status, and ownership here
- People - option to add more people to the watch list for a given ticket conversation. Note that user/ PI/
submitteremail addresses should be listed as “Requestors”. Requestors are only emailed on “Replys”, not “Comments”. Ensure your ticket has a Requestor before attempting to contact users/ PIs/submitters
- Links - option to “Merge into” another ticket number if this is part of a larger conversation. Also option to add a reference to another ticket number
Verify that this is indeed the two tickets you want to merge. It is non-reversible.
- Actions
- Reply - message the
submitter/ PI/ all watchers
- Comment - attach internal message (no
submitters, only Data Teamers)
- Open It - Open the ticket
- Stall -
submitterhas not responded in greater than 1 month
- Resolve - ticket completed
- History - message history and option to reply (to
submitterand beyond) or comment (internal message)
9.1.4 New data submission
When notified by Arcticbot about a new data submission, here are the typical steps:
- Update the Requestor under the People section based on the email given in the submission (usually the user/ PI/
submitter). You may have to google for the e-mail address if the PI did not include it in the metadata record. - Take the ticket (Actions > Take)
- Review the submission based on the checklist
- Draft an email using the template and let others review it via Slack
- Send your reply via Actions
Before opening a R script first look over the initial checklist first to identify what you will need to update in the metadata.
9.2 Initial review checklist
Before responding to a new submission use this checklist to review the submission. When your are ready to respond use the initial email template and insert comments and modify as needed.
9.2.0.1 Sensitive Data
If any of the below is in the dataset, please alert the #arctica team know before proceeding.
- Check if there is any sensitive information or personal identifying information in the data (eg. Names)
- Can the data be disaggregated and de-anonymized? (eg. a small sample size and individuals could be easily identified by their answers)
- Dryad Human Subject data guidelines can be a good place to start
Common Cases:
- Social Science: Any dataset involving human subjects (may include awards awarded by ASSP and topics such as COVID-19)
- Archaeology: archaeological site location information, which is protected from public access by law
- Biology: protected species location coordinates
9.2.0.2 Data citations
- If the dataset appears to be in a publication please (might be in the abstract) make sure that those citations are registered.
9.2.0.3 Title
- WHAT, WHERE, and WHEN:
- Is descriptive of the work (provides enough information to understand the contents at a general scientific level), AND includes temporal coverage
- Provides a location of the work from the local to state or country level
- Provides a time frame of the work
- NO UNDEFINED ACRONYMS, ABBREVIATIONS, nor INITIALISMS unless approved of as being more widely-known in that form than spelled out
9.2.0.4 Abstract
- Describes the DATA as well as:
- The motivation (purpose) of the study
- Where and when the research took place
- At least one sentence summarizing general methodologies
- NO UNDEFINED ACRONYMS, ABBREVIATIONS, nor INITIALISMS unless approved of as being more widely-known in that form than spelled out
- At least 100 words total
- tags such as
<superscript>2</superscript>and<subscript>2</subscript>can be used for nicer formatting
- tags such as
- Any citations to papers can be registered with us
9.2.0.6 Data
- Data is normalized (if not suggest to convert the data if possible)
- At least one data file, or an identifier to the files at another approved archive, unless funded by ASSP (Arctic Social Sciences Program)
- No xls/xlsx files (or other proprietary files)
- File contents and relationships among files are clear
- Each file is well NAMED and DESCRIBED and clearly differentiated from all others
- All attributes in EML match attribute names in respective data files EXACTLY, are clearly defined, have appropriate units, and are in the same order as in the file. Quality control all
dimensionlessunits. - Missing value codes are explained (WHY are the data absent?)
- If it is a
.rarfile -> scan the file - If there is the unit tons make sure to ask if it is metric tons or imperical tons if not clarified already
9.2.0.7 People & Parties
- At least one contact and one creator with a name, email address, and ORCID iD
9.2.0.8 Coverages
- Includes coverages that make sense
- Temporal coverage - Start date BEFORE end date
- Geologic time scales are added if mentioned in metadata (e.g. 8 Million Years or a name of a time period like Jurassic)
- Spatial coverage matches geographic description (check hemispheres)
- Geographic description is from the local to state or country level, at the least
- Taxonomic coverage if appropriate
9.2.0.9 Project Information
- At least one FUNDING number
- Title, personnel, and abstract match information from the AWARD (not from the data package)
9.2.0.10 Methods
- This section is REQUIRED for ALL NSF-FUNDED data packages
- Enough detail is provided such that a reasonable scientist could interpret the study and data for reuse without needing to consult the researchers, nor any other resources
9.2.0.11 Portals
- If there are multiple submissions from the same people/project let them know about the portals feature
- If this is part of a portal make sure this dataset can be found there. Additional steps might be needed to get that to work. Please consult Jeanette and see the data portals section.
9.3 Processing templates
We have developed some partially filled R scripts to get you started on working on your first dataset. They outline common functions used in processing a dataset. However, it will differ depending on the dataset.
You can use this template where you can fill in the blanks to get familiar with the functions we use and workflow at first. We also have a more minimal example A filled example as a intermediate step. You can look at the filled example if you get stuck or message the #datateam.
In addition, you may find this cheat sheet of data team R functions helpful.
Once you have updated the dataset to your satisfaction and reviewed the Final Checklist, post the link to the dataset on #datateam for peer review.
9.4 Final Checklist
You can click on the assessment report on the website to for a general check. Fix anything you see there.
Send the link over slack for peer review by your fellow datateam members. Usually we look for the following (the list is not exhaustive):
9.4.3 General EML
- Ethical Research Practice section is completed
- Publisher and system information have been added:
9.4.4 Title
- Include geographic and temporal coverage (when and where data was collected)
- Abbreviations are removed or defined
9.4.5 Abstract
- longer than 100 words
- Abbreviations are removed or defined. No garbled text
- Tags such as
<superscript>2</superscript>and<subscript>2</subscript>can be used for nicer formatting
9.4.6 DataTable / OtherEntity / SpatialVectors
- In the correct one: DataTable / OtherEntity / SpatialVector / SpatialRaster for the file type
- entityDescription - longer than 5 words and unique
- physical present and up-to-date and format is correct
9.4.6.1 Attribute Table
- Complete
- attributeDefinitions longer than 3 words
- Variables match what is in the file
- Measurement domain - if appropirate (ie dateTime correct)
- Missing Value Code - accounted for if applicable
- Semantic Annotation - appropriate semantic annotations added, especially for spatial and temporal variables: lat, lon, date etc.
- Custom units were created if necessary
9.4.7 People
- Complete information for each person in each section
- includes ORCID and e-mail address for all contacts
- people repeated across sections have consistent information
9.4.8 Geographic region
- the map looks correct and matches the geographic description
- check if negatives (-) are missing
9.4.9 Project
- If it is an NSF award you can use the helper function:
doc$dataset$project <- eml_nsf_to_project(awards)
- for other awards that need to be set manually, see the set project page
9.4.11 Check EML Version
- Currently using:
eml-2.2.0(as of July 30 2020) - Review to see if the EML version is set correctly by reviewing the
doc$`@context`that it is indeed 2.2.0 under eml - Re-run your code again and have the line
emld::eml_version("eml-2.2.0")at the top - Make sure the system metadata is also 2.2.0
9.4.12 Access
- If necessary, granted access to PI using
set_rights_and_access()- make sure it is
http://(no s)
- make sure it is
- note if it is a part of portals there might be specific access requirements for it to be visible using
set_access()
9.4.13 SFTP Files
- If there are files transferred to us via SFTP, delete those files once they have been added to the dataset and when the ticket is resolved
9.4.14 Updated datasets
All the above applies. These are some areas to do a closer check when users update with a new file:
- New data was added
- Temporal Coverage and Title
- Confirm if new data used same methods or if methods need updating
- Files were replaced
- update physical and entityName
- double-check attributes are the same
- check for any new missing value codes that should be accounted for
- Was the dataset published before 2021?
- update project info, annotations
- Glance over entire page for any small mistakes (ie. repeated additionalMetadata, any missed &s, typos)
After all the revisions send the link to the PI in an email through RT. Send the draft of the email to Daphne or Jeanette on Slack.
9.5 Email templates
This section covers new data packages submitted. For other inquiries see the PI FAQ templates
Please think critically when using these canned replies rather than just blindly sending them. Typically, content should be adjusted/ customized for each response to be as relevant, complete, and precise as possible.
In your first few months, please run email drafts by the #datateam Slack and get approval before sending.
Remember to consult the submission guidelines for details of what is expected.
Quick reference:
9.5.1 Initial email template
Hello [NAME OF REQUESTOR], Thank you for your recent submission to the NSF Arctic Data Center!
From my preliminary examination of your submission I have noticed a few items that I would like to bring to your attention. We are here to help you publish your submission, but your continued assistance is needed to do so. See comments below:
[COMMENTS HERE]
After we receive your responses, we can make the edits on your behalf, or you are welcome to make them yourself using our user interface.
Best,
[YOUR NAME]
9.5.3 Final email templates
9.5.3.1 Asking for approval
Hi [submitter],
I have updated your data package and you can view it here after logging in: [URL]
Please review and approve it for publishing or let us know if you would like anything else changed. For your convenience, if we do not hear from you within a week we will proceed with publishing with a DOI.
After publishing with a DOI, any further changes to the dataset will result in a new DOI. However, any previous DOIs will still resolve and point the user to the newest version.
Please let us know if you have any questions.
9.5.3.2 DOI and data package finalization comments
Replying to questions about DOIs
We attribute DOIs to data packages as one might give a DOI to a citable publication. Thus, a DOI is permanently associated with a unique and immutable version of a data package. If the data package changes, a new DOI will be created and the old DOI will be preserved with the original version.
DOIs and URLs for previous versions of data packages remain active on the Arctic Data Center (will continue to resolve to the data package landing page for the specific version they are associated with), but a clear message will appear at the top of the page stating that “A newer version of this dataset exists” with a hyperlink to that latest version. With this approach, any past uses of a DOI (such as in a publication) will remain functional and will reference the specific version of the data package that was cited, while pointing users to the newest version if one exists.
Clarification of updating with a DOI and version control
We definitely support updating a data package that has already been assigned a DOI, but when we do so we mark it as a new revision that replaces the original and give it its own DOI. We do that so that any citations of the original version of the data package remain valid (i.e.: after the update, people still know exactly which data were used in the work citing it).
9.5.3.3 Resolve the ticket
Sending finalized URL and dataset citation before resolving ticket
[NOTE: the URL format is very specific here, please try to follow it exactly (but substitute in the actual DOI of interest)]
Here is the link and citation to your finalized data package:
First Last, et al. 2021. Title. Arctic Data Center. doi:10.18739/A20X0X.
If in the future there is a publication associated with this dataset, we would appreciate it if you could register the DOI of your published paper with us by using the Citations button right below the title at the dataset landing page. We are working to build our catalog of dataset citations in the Arctic Data Center.
Please let us know if you need any further assistance.
9.5.4 Additional email templates
9.5.4.1 Deadlines
If the PI is checking about dates/timing: > [give rough estimate of time it might take] > Are you facing any deadlines? If so, we may be able to expedite publication of your submission.
9.5.4.2 Pre-assigned DOI
If the PI needs a DOI right away:
We can provide you with a pre-assigned DOI that you can reference in your paper, as long as your submission is not facing a deadline from NSF for your final report. However, please note that it will not become active until after we have finished processing your submission and the package is published. Once you have your dataset published, we would appreciate it if you could register the DOI of your published paper with us by using the citations button beside the orange lock icon. We are working to build our catalog of dataset citations in the Arctic Data Center.
9.5.4.3 Sensitive Data
Which of the following categories best describes the level of sensitivity of your data?
A. Non-sensitive data None of the data includes sensitive or protected information. Proceed with uploading data. B. Some or all data is sensitive but has been made safe for open distribution Sensitive data has been de-identified, anonymized, aggregated, or summarized to remove sensitivities and enable safe data distribution. Examples include ensuring that human subjects data, protected species data, archaeological site locations and personally identifiable information have been properly anonymized, aggregated and summarized. Proceed with uploading data, but ensure that only data that are safe for public distribution are uploaded. Address questions about anonymization, aggregation, de-identification, and data embargoes with the data curation support team before uploading data. Describe these approaches in the Methods section. C. Some or all data is sensitive and should not be distributed The data contains human subjects data or other sensitive data. Release of the data could cause harm or violate statutes, and must remain confidential following restrictions from an Institutional Review Board (IRB) or similar body. Do NOT upload sensitive data. You should still upload a metadata description of your dataset that omits all sensitive information to inform the community of the dataset’s existence. Contact the data curation support team about possible alternative approaches to safely preserve sensitive or protected data.
- Ethical Research Procedures. Please describe how and the extent to which data collection procedures followed community standards for ethical research practices (e.g., CARE Principles). Be explicit about Institutional Review Board approvals, consent waivers, procedures for co-production, data sovereignty, and other issues addressing responsible and ethical research. Include any steps to anonymize, aggregate or de-identify the dataset, or to otherwise create a version for public distribution.
9.5.4.4 Asking for dataset access
As a security measure we ask that we get the approval from the original submitter of the dataset prior to granting edit permissions to all datasets.
9.5.4.5 No response from the researcher
Please email them before resolving a ticket like this:
We are resolving this ticket for bookkeeping purposes, if you would like to follow up please feel free to respond to this email.
9.5.4.6 Recovering Dataset submissions
To recover dataset submissions that were not successful please do the following:
- Go to https://arcticdata.io/catalog/drafts
- Find your dataset and download the corresponding file
- Send us the file in an email
9.5.4.7 Custom Search Link
You could also use a permalink like this to direct users to the datasets: https://arcticdata.io/catalog/data/query="your search query here” for example: https://arcticdata.io/catalog/data/query=Beaufort%20Lagoon%20Ecosystems%20LTER
9.5.4.8 Adding metadata via R
KNB does not support direct uploading of EML metadata files through the website (we have a webform that creates metadata), but you can upload your data and metadata through R.
Here are some training materials we have that use both the
EMLanddatapackpackages. It explains how to set your authentication token, build a package from metadata and data files, and publish the package to one of our test sites. I definitely recommend practicing on a test site prior to publishing to the production site your first time through. You can point to the KNB test node (dev.nceas.ucsb.edu) using this command:d1c <- D1Client("STAGING2", "urn:node:mnTestKNB")
If you prefer, there are Java, Python, MATLAB, and Bash/cURL clients as well.
9.5.4.9 Finding multiple data packages
If linking to multiple data packages, you can send a link to the profile associated with the submitter’s ORCID iD and it will display all their data packages. e.g.: https://arcticdata.io/catalog/profile/http://orcid.org/0000-0002-2604-4533
9.5.4.10 NSF ARC data submission policy
Please find an overview of our submission guidelines here: https://arcticdata.io/submit/, and NSF Office of Polar Programs policy information here: https://www.nsf.gov/pubs/2016/nsf16055/nsf16055.jsp.
Investigators should upload their data to the Arctic Data Center (https://arcticdata.io), or, where appropriate, to another community endorsed data archive that ensures the longevity, interpretation, public accessibility, and preservation of the data (e.g., GenBank, NCEI). Local and university web pages generally are not sufficient as an archive. Data preservation should be part of the institutional mission and data must remain accessible even if funding for the archive wanes (i.e., succession plans are in place). We would be happy to discuss the suitability of various archival locations with you further. In order to provide a central location for discovery of ARC-funded data, a metadata record must always be uploaded to the Arctic Data Center even when another community archive is used.
9.5.4.11 Linking ORCiD and LDAP accounts
First create an account at orcid.org/register if you have not already. After that account registration is complete, login to the KNB with your ORCID iD here: https://knb.ecoinformatics.org/#share. Next, hover over the icon on the top right and choose “My Profile”. Then, click the “Settings” tab and scroll down to “Add Another Account”. Enter your name or username from your Morpho account and select yourself (your name should populate as an option). Click the “+”. You will then need to log out of knb.ecoinformatics.org and then log back in with your old LDAP account (click “have an existing account”, and enter your Morpho credentials with the organization set to “unaffiliated”) to finalize the linkage between the two accounts. Navigate to “My Profile” and “Settings” to confirm the linkage.
After completing this, all of your previously submitted data pacakges should show up on your KNB “My Profile” page, whether you are logged in using your ORCiD or Morpho account, and you will be able to submit data either using Morpho or our web interface.
Or, try reversing my instructions - log in first using your Morpho account (by clicking the “existing account” button and selecting organization “unaffiliated”), look for your ORCiD account, then log out and back in with ORCiD to confirm the linkage.
Once the dataset is approved by the PI and there are no further changes, publish the dataset with a doi.
9.6 Categorize datasets
As a final step we will categorize the dataset you processed. We are trying to categorize datasets so we can have a rough idea of what kinds of datasets we have at the Arctic Data Center. We will grant you access to the google sheet that has all of the categorized datasets
We will categorize each dataset into one of the predefined themes (ie. biology, ecology etc.). Definition of the themes can be found in the google sheet
Run the following line with your doi and themes as a list.
9.7 Congrats!
Congratulations on finishing your first ticket! You can head over to the the repository, data-processing to get your ticket processing code reviewed by the team so we can learn from each other!
9.5.2 Comment templates based on what is missing
9.5.2.1 Portals
Multiple datasets under the same project - suggest data portal feature
If they ask to nest the dataset
9.5.2.2 Dataset citations
9.5.2.3 Title
Provides the what, where, and when of the data
Does not use acronyms
9.5.2.4 Abstract
Describes DATA in package (ideally > 100 words)
Offer this if submitter is reluctant to change:
9.5.2.5 Keywords
9.5.2.6 Data
Sensitive Data
We will need to ask these questions manually until the fields are added to the webform.
Once we have the ontology this question can be asked:
Non-sensitive data - None of the data includes sensitive or protected information.
Some or all data is sensitive with minimal risk - Sensitive data has been de-identified, anonymized, aggregated, or summarized to remove sensitivities and enable safe data distribution. Examples include ensuring that human subjects data, protected species data, archaeological site locations and personally identifiable information have been properly anonymized, aggregated and summarized.
Some or all data is sensitive with significant risk - The data contains human subjects data or other sensitive data. Release of the data could cause harm or violate statutes, and must remain confidential following restrictions from an Institutional Review Board (IRB) or similar body.
Adding provenance
At least one data file
Open formats
Example using xlsx. Tailor this reponse to the format in question.
Zip files
File contents and relationships among files are clear
Data layout
We try not to prescribe a way the researchers must format their data as long as reasonable. However, in extreme cases (for example Excel spreadsheets with data and charts all in one sheet) we will want to kindly ask them to reformat.
9.5.2.7 Attributes
Identify which attributes need additional information. If they are common attributes like date and time we do not need further clarification.
Checklist for the datateam in reviewing attributes (NetCDF, CSV, shapefiles, or any other tabular datasets):
Helpful templates: > We would like your help in defining some of the attributes. Could you write a short description or units for the attributes listed? [Provide a the attribute names in list form] > Could you describe ____? > Please define “XYZ”, including the unit of measure. > What are the units of measurement for the columns labeled “ABC” and “XYZ”?
Missing value codes
9.5.2.8 Funding
All NSF funded datasets need a funding number. Non-NSF funded datasets might not have funding numbers, depending on the funding organization.
9.5.2.9 Methods
We noticed that methods were missing from the submission. Submissions should include the following:
Note - this includes software submissions as well (see https://arcticdata.io/submit/#metadata-guidelines-for-software)
A full example - New Submission: methods, excel to csv, and attributes