Chapter 4 Editing EML
This chapter is a practical tutorial for using R to read, edit, write, and validate EML documents. Much of the information here can also be found in the vignettes for the R packages used in this section (e.g. the EML package).
Most of the functions you will see in this chapter will use the arcticdatautils and EML packages.
This chapter will be longest of all the sections! This is a reminder to take frequent breaks when completing this section. If you struggle with getting a piece of code to work more than 10 minutes, reach out to your supervisor for help.
When using R to edit EML documents, run each line individually by highlighting the line and using CTRL+ENTER). Many EML functions only need to be ran once, and will either produce errors or make the EML invalid if run multiple times.
4.1 Edit an EML element
There are multiple ways to edit an EML element.
4.1.1 Edit EML with strings
The most basic way to edit an EML element would be to navigate to the element and replace it with something else. Easy!
For example, to change the title one could use the following command:
If the element you are editing allows for multiple values, you can pass it a list of character strings. Since a dataset can have multiple titles, we can do this:
However, this isn’t always the best method to edit the EML, particularly if the element has sub-elements. Adding directly to doc without a helper function can overwrite these parts of the doc that we need.
4.1.2 Edit EML with the “EML” package
To edit a section where you are not 100% sure of the sub-elements, using the eml$elementName() helper functions from the EML package will pre-populate the options for you if you utilize the RStudio autocomplete functionality. The arguments in these functions show the available slots for any given EML element. For example, typing doc$dataset$abstract <- eml$abstract()<TAB> will show you that the abstract element can take either the section or para sub-elements.

doc$dataset$abstract <- eml$abstract(para = "A concise but thorough description of the who, what, where, when, why, and how of a dataset.")This inserts the abstract with a para element in our dataset, which we know from the EML schema is valid.
Note that the above is equivalent to the following generic construction:
doc$dataset$abstract <- list(para = "A concise but thorough description of the who, what, where, when, why, and how of a dataset.")The eml() family of functions provides the sub-elements as arguments, which is extremely helpful, but functionally all it is doing is creating a named list, which you can also do using the list function.
4.1.3 Edit EML with objects
A final way to edit an EML element would be to build a new object to replace the old object. To begin, you might create an object using an eml helper function. Let’s take keywords as an example. Sometimes keyword lists in a metadata record will come from different thesauruses, which you can then add in series (similar to the way we added multiple titles) to the element keywordSet.
We start by creating our first set of keywords and saving it to an object.
kw_list_1 <- eml$keywordSet(keywordThesaurus = "LTER controlled vocabulary",
keyword = list("bacteria", "carnivorous plants", "genetics", "thresholds"))Which returns:
$keyword
$keyword[[1]]
[1] "bacteria"
$keyword[[2]]
[1] "carnivorous plants"
$keyword[[3]]
[1] "genetics"
$keyword[[4]]
[1] "thresholds"
$keywordThesaurus
[1] "LTER controlled vocabulary"We create the second keyword list similarly:
kw_list_2 <- eml$keywordSet(keywordThesaurus = "LTER core area",
keyword = list("populations", "inorganic nutrients", "disturbance"))Finally, we can insert our two keyword lists into our EML document just like we did with the title example above, but rather than passing character strings into list(), we will pass our two keyword set objects.
Note that you must use the function
list here and not the c() function. The
reasons for this are complex, and due to some technical subtlety in R -
but the gist of the issue is that the c() function can
behave in unexpected ways with nested lists, and frequently will
collapse the nesting into a single level, resulting in invalid EML.
4.2 FAIR data practices
The result of these function calls won’t show up on the webpage, but they will add a publisher element to the dataset element and a system to all of the entities based on what the PID is. This will help make our metadata more FAIR (Findable, Accessible, Interoperable, Reusable).
These two functions come from the arcticatautils package, an R package we wrote to help with some very specific data processing tasks in our team.
Add these function calls to all of your EML processing scripts.
4.3 Edit attributeLists
Attributes are descriptions of variables, typically columns or column names in tabular data. Attributes are stored in an attributeList element. When editing attributes in R, we convert the attribute list information to data frame (table) format so that it is easier to edit. When editing attributes you will need to create one to three data frame objects:
- A data.frame of attributes
- A data.frame of custom units (if applicable)
- A data.frame of factors (if applicable)
The attributeList is an element within one of 4 different types of entity objects. An entity corresponds to a file, typically. Multiple entities (files) can exist within a dataset. The 4 different entity types are:
dataTable(most common for us)spatialVectorspatialRasterotherEntity
Please note that submitting attribute information through the website will store them in an otherEntity object by default. We prefer to store them in a dataTable object for tabular data or a spatialVector or spatialRaster object for geospatial data.
To edit or examine an existing attribute list already in an EML file, you can use the following commands, where i represents the index of the series element you are interested in. Note that if there is only one item in the series (i.e. there is only one dataTable), you should just call doc$dataset$dataTable, as in this case doc$dataset$dataTable[[1]] will return the first sub-element of the dataTable (the entityName)
# If they are stored in an otherEntity (submitted from the website by default)
attribute_tables <- EML::get_attributes(doc$dataset$otherEntity[[i]]$attributeList)
# Or if they are stored in a dataTable (usually created by a datateam member)
attribute_tables <- EML::get_attributes(doc$dataset$dataTable[[i]]$attributeList)The get_attributes() function returns the attribute_tables object, which is a list of the three data frames mentioned above. The data frame with the attributes is called attribute_tables$attributes.
The other 2 data frames can also be accessed by using the $ operator and the name of the table. The custom units table is called attribute_tables$units and the factors table is called attribute_tables$factors. If there are no custom units or factors, these tables will be empty data frames.
4.3.1 Edit attributes
Attribute information should be stored in a data.frame with the following columns:
- attributeName: The name of the attribute as listed in the csv. Required. e.g.: “c_temp”
- attributeLabel: A descriptive label that can be used to display the name of an attribute. It is not constrained by system limitations on length or special characters. Optional. e.g.: “Temperature (Celsius)”
- attributeDefinition: Longer description of the attribute, including the required context for interpreting the
attributeName. Required. e.g.: “The near shore water temperature in the upper inter-tidal zone, measured in degrees Celsius.” - measurementScale: One of: nominal, ordinal, dateTime, ratio, interval. Required.
- nominal: unordered categories or text. e.g.: (Male, Female) or (Yukon River, Kuskokwim River)
- ordinal: ordered categories. e.g.: Low, Medium, High
- dateTime: date or time values from the Gregorian calendar. e.g.: 01-01-2001
- ratio: measurement scale with a meaningful zero point in nature. Ratios are proportional to the measured variable. e.g.: 0 Kelvin represents a complete absence of heat. 200 Kelvin is half as hot as 400 Kelvin. 1.2 meters per second is twice as fast as 0.6 meters per second.
- interval: values from a scale with equidistant points, where the zero point is arbitrary. This is usually reserved for degrees Celsius or Fahrenheit, or any other human-constructed scale. (e.g. there is still heat at 0° Celsius; 12° Celsius is NOT half as hot as 24° Celsius.)
- domain: One of:
textDomain,enumeratedDomain,numericDomain,dateTime. Required.- textDomain: text that is free-form, or matches a pattern
- enumeratedDomain: text that belongs to a defined list of codes and definitions. (e.g. CASC = Cascade Lake, HEAR = Heart Lake)
- dateTimeDomain:
dateTimeattributes - numericDomain: attributes that are numbers (either
ratioorinterval)
- formatString: Required for
dateTime, NA otherwise. Format string for dates, e.g. “DD/MM/YYYY”. - definition: Required for
textDomain, NA otherwise. Defines a format for attributes that are a character string. (e.g. “Any text” or “7-digit alphanumeric code”) - unit: Required for
numericDomain, NA otherwise. Unit string. If the unit is not a standard unit, a warning will appear when you create the attribute list, saying that it has been forced into a custom unit. Use caution here to make sure the unit really needs to be a custom unit. A list of standard units can be found using:standardUnits <- EML::get_unitList()then runningView(standardUnits$units). - numberType: Required for
numericDomain, NA otherwise. Options arereal,natural,whole, andinteger.- real: positive and negative fractions and integers (…-1,-0.25,0,0.25,1…)
- natural: non-zero positive integers (1,2,3…)
- whole: positive integers and zero (0,1,2,3…)
- integer: positive and negative integers and zero (…-2,-1,0,1,2…)
- missingValueCode: Code for missing values (e.g.: ‘-999’, ‘NA’, ‘NaN’). NA otherwise. Note that an NA missing value code should be a string, ‘NA’, and numbers should also be strings, ‘-999.’
- missingValueCodeExplanation: Explanation for missing values, NA if no missing value code exists.
You can create attributes manually by typing them out in R following a workflow similar to the one below:
attributes <- data.frame(
attributeName = c('Date', 'Location', 'Region','Sample_No', 'Sample_vol', 'Salinity', 'Temperature', 'sampling_comments'),
attributeDefinition = c('Date sample was taken on', 'Location code representing location where sample was taken','Region where sample was taken', 'Sample number', 'Sample volume', 'Salinity of sample in PSU', 'Temperature of sample', 'comments about sampling process'),
measurementScale = c('dateTime', 'nominal','nominal', 'nominal', 'ratio', 'ratio', 'interval', 'nominal'),
domain = c('dateTimeDomain', 'enumeratedDomain','enumeratedDomain', 'textDomain', 'numericDomain', 'numericDomain', 'numericDomain', 'textDomain'),
formatString = c('MM-DD-YYYY', NA,NA,NA,NA,NA,NA,NA),
definition = c(NA,NA,NA,'Six-digit code', NA, NA, NA, 'Any text'),
unit = c(NA, NA, NA, NA,'milliliter', 'dimensionless', 'celsius', NA),
numberType = c(NA, NA, NA,NA, 'real', 'real', 'real', NA),
missingValueCode = c(NA, NA, NA,NA, NA, NA, NA, 'NA'),
missingValueCodeExplanation = c(NA, NA, NA,NA, NA, NA, NA, 'no sampling comments'))However, typing this out in R can be a major pain. Luckily, there’s a Shiny app that you can use to build attribute information. You can use the app to build attributes from a data file loaded into R (recommended, as the app will auto-fill some fields for you), to edit an existing attribute table, or to create attributes from scratch. Use the following commands to create or modify attributes.
Use the following commands to create or modify attributes. These commands will launch a “Shiny” app in your web browser.
#first download the CSV in your data package from Exercise #2
data_pid <- selectMember(dp, name = "sysmeta@fileName", value = ".csv")
data <- read.csv(text=rawToChar(getObject(d1c_test@mn, data_pid)))# From data (recommended)
attribute_tables <- EML::shiny_attributes(data = data)
# From scratch
attribute_tables <- EML::shiny_attributes()
# From an existing attribute list
attribute_tables <- get_attributes(doc$dataset$dataTable[[i]]$attributeList)
attribute_tables <- EML::shiny_attributes(attributes = attribute_tables$attributes)Once you are done editing a table in the browser app, be sure to quit the app by pressing the red “Quit App” button in the top right corner of the page. This is necessary to save your work to the attribute_tables variable in R.
If you close the Shiny app tab in your browser instead of using the “Quit App” button, your work will not be saved. R will think that the Shiny app is still open, and you will not be able to run other code. You can tell if R is confused if you have closed the Shiny app and the bottom line in the console still says Listening on http://.... If this happens, press the red stop sign button on the right hand side of the console window in order to interrupt R.
The tables you constructed in the app will be assigned to the attribute_tables variable as a list of data frames (one for attributes, factors, and units). Be careful to not overwrite your completed attribute_tables object when trying to make edits. The last line of code can be used in order to make edits to an existing attribute_tables object.
Alternatively, each table can be exported to a csv file by clicking the Download button. If you downloaded the table, read the table back into your R session and assign it to a variable in your script (e.g. attributes <- data.frame(...)), or just use the variable that shiny_attributes returned.
For simple attribute corrections, datamgmt::edit_attribute() allows you to edit the slots of a single attribute within an attribute list. To use this function, pass an attribute through datamgmt::edit_attribute() and fill out the parameters you wish to edit/update. An example is provided below where we are changing attributeName, domain, and measurementScale in the first attribute of a dataset. After completing the edits, insert the new version of the attribute back into the EML document.
4.3.2 Edit custom units
EML has a set list of units that can be added to an EML file. These can be seen by using the following code:
Search the units list for your unit before attempting to create a custom unit. You can search part of the unit you can look up part of the unit (e.g. meters in the table) to see if there are any matches.
If you have units that are not in the standard EML unit list, you will need to build a custom unit list. Attribute tables with custom units listed will generate a warning indicating that a custom unit will need to be described.
A unit typically consists of the following fields:
- id: The
unit id(ids are camelCased) - unitType: The
unitType(runView(standardUnits$unitTypes)to see standardunitTypes) - parentSI: The
parentSIunit (e.g. for kilometerparentSI= “meter”). The parentSI does not need to be part of the unitList. - multiplierToSI: Multiplier to the
parentSIunit (e.g. for kilometermultiplierToSI= 1000) - name: Unit abbreviation (e.g. for kilometer
name= “km”) - description: Text defining the unit (e.g. for kilometer
description= “1000 meters”)
To manually generate the custom units list, create a dataframe with the fields mentioned above. An example is provided below that can be used as a template:
custom_units <- data.frame(
id = c('siemensPerMeter', 'decibar'),
unitType = c('resistivity', 'pressure'),
parentSI = c('ohmMeter', 'pascal'),
multiplierToSI = c('1','10000'),
abbreviation = c('S/m','decibar'),
description = c('siemens per meter', 'decibar'))Custom units can also be created in the Shiny app, under the “units” tab. They cannot be edited again in the shiny app once created.
Using EML::get_unit_id for custom units will also generate valid EML unit ids.
Custom units are then added to additionalMetadata using the following command:
4.3.3 Edit factors
For attributes that are enumeratedDomains, a table is needed with three columns: attributeName, code, and definition.
- attributeName should be the same as the
attributeNamewithin the attribute table and repeated for all codes belonging to a common attribute. - code should contain all unique values of the given
attributeNamethat exist within the actual data. - definition should contain a plain text definition that describes each code.
To build factors by hand, you use the named character vectors and then convert them to a data.frame as shown in the example below. In this example, there are two enumerated domains in the attribute list - “Location” and “Region”.
Location <- c(CASC = 'Cascade Lake',
CHIK = 'Chikumunik Lake',
HEAR = 'Heart Lake',
NISH = 'Nishlik Lake' )
Region <- c(W_MTN = 'West region, locations West of Eagle Mountain',
E_MTN = 'East region, locations East of Eagle Mountain')The definitions are then written into a data.frame using the names of the named character vectors and their definitions.
factors <- rbind(data.frame(attributeName = 'Location', code = names(Location), definition = unname(Location)),
data.frame(attributeName = 'Region', code = names(Region), definition = unname(Region)))Factors can also be created in the Shiny app, under the “factors” tab. They cannot be edited again in the shiny app once created.
4.3.4 Finalize attributeList
Once you have built your attributes, factors, and custom units, you can add them to EML objects. Attributes and factors are combined to form an attributeList using set_attributes():
# Create an attributeList object
attributeList <- EML::set_attributes(attributes = attribute_tables$attributes,
factors = attribute_tables$factors) This attributeList object can then be checked for errors and added to a dataTable in the EML document.
At this point, it’s good to check if everything is valid by using the eml_validate(doc) function. If there are errors, they will be listed in the console and you can go back and fix them. If there are no errors, you should see [1] TRUE in the console.
Remember to use:
d1c_test <- dataone::D1Client(“STAGING”, “urn:node:mnTestARCTIC”)
d1c_test@mn
4.4 Set physical
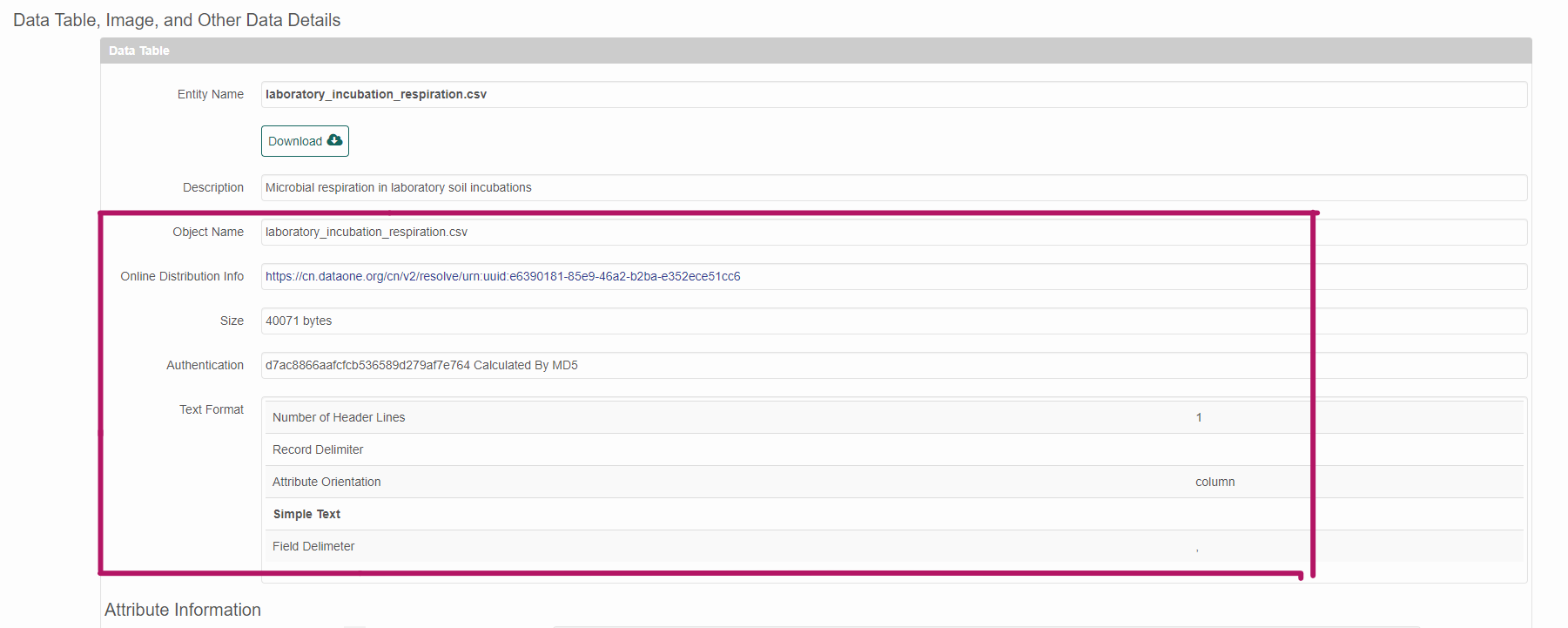
A physical is a description of the physical elements of the data objects. This includes things like the file name, file size, data format, and for tabular data, the number of header lines and attribute orientation. The physical is a required element for all entities in EML.
To set the physical aspects of a data object, use the following commands to build a physical object from a data PID that exists in your package. Remember to set the member node to test.arcticdata.io!
Every entity that we upload needs a physical description added. When replacing files, the physical must be replaced as well.
The word ‘physical’ derives from database systems, which distinguish the ‘logical’ model (e.g., what attributes are in a table, etc) from the physical model (how the data are written to a physical hard disk or the serialization). So, we grouped metadata about the file (eg. data format, file size, file name) as written to disk in physical. It includes info like the file size. For CSV files, the physical describes the number of header lines and the attribute orientation.
# Get the PID of a file
data_pid <- selectMember(dp, name = "sysmeta@fileName", value = "your_file_name.csv")
# Get the physical info and store it in an object
physical <- arcticdatautils::pid_to_eml_physical(mn, data_pid)The physical object can then be checked for errors and added to the EML document.
Note that the above workflow only works if your data object already exists on the member node.
Physicals can be seen in the website representation of the EML below the entity description.
4.5 Edit dataTables
Entities that are dataTables require an attribute list. To edit a dataTable, first edit/create an attributeList and set the physical. Then create a new dataTable using the eml$dataTable() helper function as below:
dataTable <- eml$dataTable(entityName = "A descriptive name for the data (does not need to be the same as the data file)",
entityDescription = "A description of the data",
physical = physical,
attributeList = attributeList)The dataTable must then be added to the EML. How exactly you do this will depend on whether there are dataTable elements in your EML already, and how many there are. To replace whatever dataTable elements already exist, you could write:
If there is only one dataTable in your dataset, the EML package will usually “unpack” these, so that it is not contained within a list of length 1 - this means that to add a second dataTable, you cannot use the syntax doc$dataset$dataTable[[2]], since when unpacked this will contain the entityDescription as opposed to pointing to the second in a series of dataTable elements.
Confusing - I know. Not to fear though - this syntax will get you on your way, should you be trying to add a second dataTable. It takes the existing dataTable, then replaces it with a new list of 2 items: the existing dataTable and the newest dataTable.
If there is more than one dataTable in your dataset, you can return to the more straightforward construction of:
Where i is the index that you wish insert your dataTable into.
To add a list of dataTables to avoid the unpacking problem above you will need to create a list of dataTables
dts <- list() # create an empty list
for(i in seq_along(tables_you_need)){
# your code modifying/creating the dataTable here
dataTable <- eml$dataTable(entityName = dataTable$entityName,
entityDescription = dataTable$entityDescription,
physical = physical,
attributeList = attributeList)
dts[[i]] <- dataTable # add to the list
}After getting a list of dataTables, assign the resulting list to dataTable EML
By default, the online submission form adds all entities as otherEntity, even when most should probably be dataTable. You can use eml_otherEntity_to_dataTable from our arcticdatautils package to easily move items in otherEntity over to dataTable, and delete the old otherEntity.
Most tabular data or data that contain variables should be listed as a dataTable. Data that do not contain variables (eg: plain text readme files, pdfs, jpegs) should be listed as otherEntity.
4.6 Edit otherEntities
4.6.1 Remove otherEntities
To remove an otherEntity use the following command. This may be useful if a data object is originally listed as an otherEntity and then transferred to a dataTable.
4.6.2 Create otherEntities
If you need to create/update an otherEntity, make sure to publish or update your data object first (if it is not already on the DataONE MN). Then build your otherEntity.
data_pid <- selectMember(dp, "sysmeta@fileNamme", "filename.pdf")
otherEntity <- arcticdatautils::pid_to_eml_entity(d1c_test@mn, data_pid)Alternatively, you can build the otherEntity of a data object not in your package by simply inputting the data PID.
otherEntity <- arcticdatautils::pid_to_eml_entity(d1c_test@mn, "new_data_pid",
entityType = "otherEntity",
entityName = "Entity Name",
entityDescription = "Description about entity")The otherEntity must then be set to the EML, like so:
If you have more than one otherEntity object in the EML already, you can add the new one like this:
Where i is set to the number of existing entities plus one.
Remember the warning from the last section, however. If you only have one otherEntity, and you are trying to add another, you have to run:
4.7 Semantic annotations
For a brief overview of what a semantic annotation is, and why we use them check out this video.
Even more information on how to add semantic annotations to EML 2.2.0 can be found here.
There are several elements in the EML 2.2.0 schema that can be annotated:
- a
dataset - an entity (eg:
otherEntityordataTable) - an
attribute
Attribute annotations can be edited in R and also on the website. Dataset and entity annotations are only done in R.
4.7.1 How attribute annotations are used
This is a dataset that has semantic annotations included.
On the website, you can see annotations in each of the attributes in the attribute list of the files.
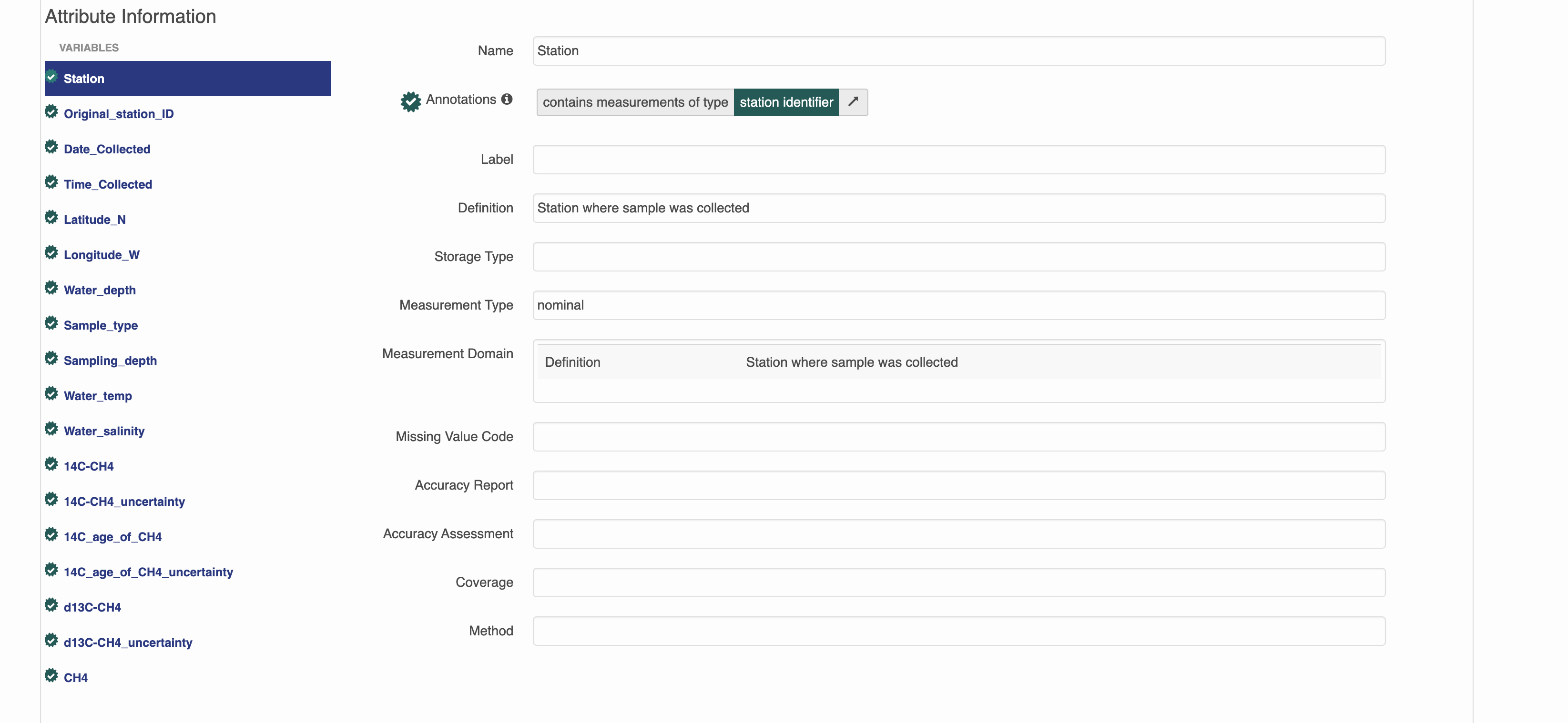
Semantic attribute annotations can be applied to spatialRasters, spatialVectors and dataTables, as all these types of files contain attributes.
4.7.1.1 Attribute-level annotations on the website editor
The website has a searchable list of attribute annotations that are grouped by category and specificity. Open your dataset on the test website from earlier and enter the attribute editor. Look through all of the available annotations for attributes..
Adding attribute annotations using the website is the simplest way. However, adding them using R and/or the Shiny app may be quicker with much larger datasets that have a lot of attributes or files.
4.7.1.2 Attribute-level annotations in R
To manually add annotations to the attributeList in R you will need information about the propertyURI and valueURI as well as a unique id for the annotation.
- The
idneeds to be unique across all attributes and across all files in the dataset too. This will be added to theidcolumn of theattributeTable. - The
propertyURIis the same for every annotation you make for the attributes. It will be “http://ecoinformatics.org/oboe/oboe.1.2/oboe-core.owl#containsMeasurementsOfType” and - The
propertyLabelwill be “contains measurements of type”. This is the predicate in the sentence that describes the annotation. - The
valueURIis the URI of the term you select from an ontology that best describes your attribute. - The
valueLabelis the label of the term you select from an ontology that best describes your attribute.
Annotations are essentially composed of a sentence, which contains a subject (the attribute), predicate (propertyURI),
and object (valueURI). Because of the way our search interface is built, for now we will be using attribute annotations that have a propertyURI label of “contains measurements of type”.
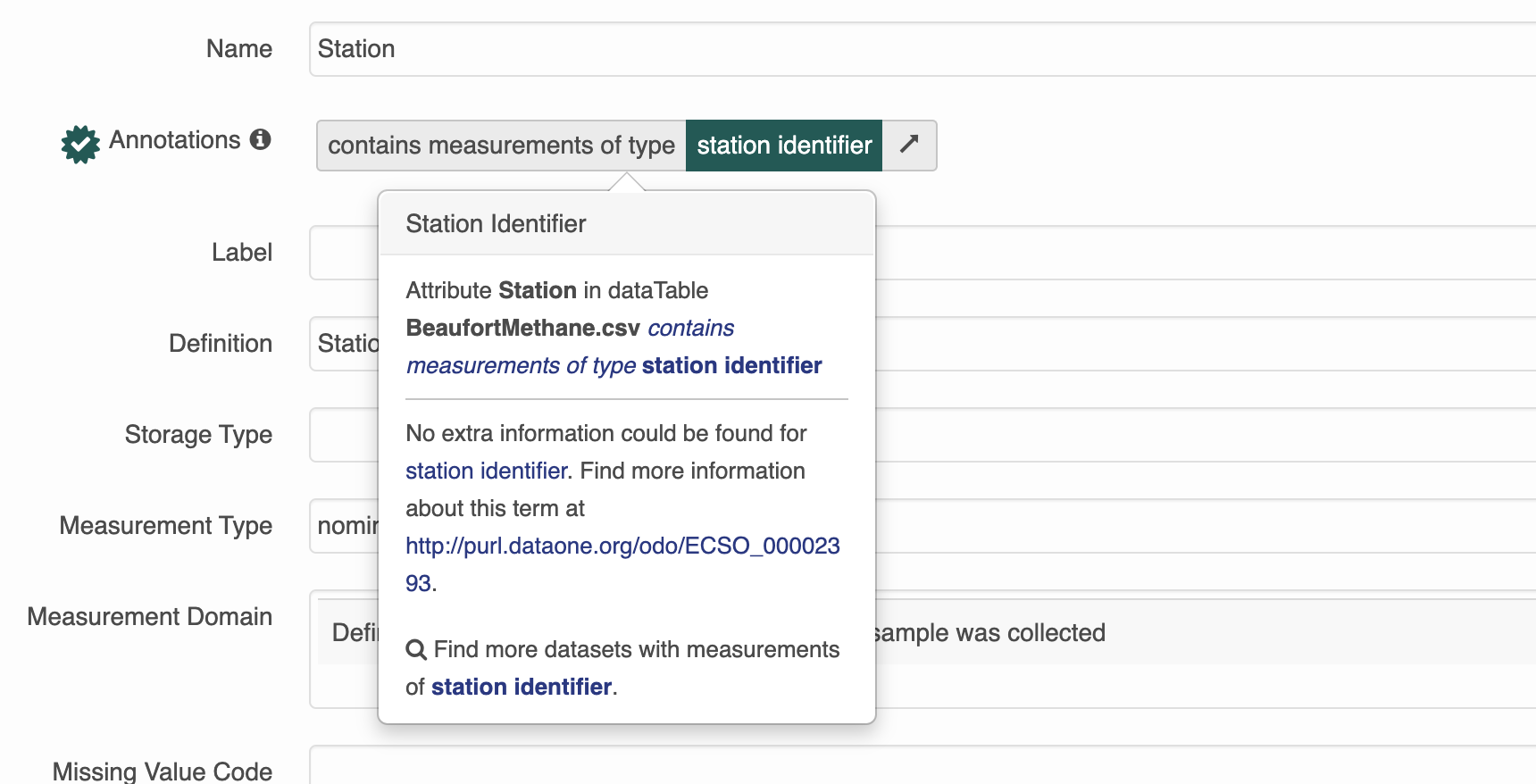
Here is what an annotation for an attribute looks like in R. Note that both the propertyURI and valueURI have both a label, and the URI itself.
$id
[1] "ODBcOyaTsg"
$propertyURI
$propertyURI$label
[1] "contains measurements of type"
$propertyURI$propertyURI
[1] "http://ecoinformatics.org/oboe/oboe.1.2/oboe-core.owl#containsMeasurementsOfType"
$valueURI
$valueURI$label
[1] "Distributed Biological Observatory region identifier"
$valueURI$valueURI
[1] "http://purl.dataone.org/odo/ECSO_00002617"This shows that within the attributeList, the ith attribute of the ith dataTable has an annotation with
- a unique id of “ODBcOyaTsg”,
- a propertyURI with a label of “contains measurements of type” and a URI of “http://ecoinformatics.org/oboe/oboe.1.2/oboe-core.owl#containsMeasurementsOfType”,
- and a valueURI with a label of “Distributed Biological Observatory region identifier” and a URI of “http://purl.dataone.org/odo/ECSO_00002617”.
4.7.2 How to add an annotation
1. Decide which variable to annotate
The goal for the datateam is to start annotating every dataset that comes in. Please make sure to add semantic annotations to spatial and temporal features such as latitude, longitude, site name and date and aim to annotate as many attributes as possible.
2. Find an appropriate valueURI
The next step is to find an appropriate value to fill in the blank of the sentence: “this attribute contains measurements of _____.”
There are several ontologies (controlled vocabularies) to search in. In order of most to least likely to be relevant to the Arctic Data Center they are:
- The Ecosystem Ontology (ECSO)
- this was developed at NCEAS, and has many terms that are relevant to ecosystem processes, especially those involving carbon and nutrient cycling
- The Environment Ontology (EnVO)
- this is an ontology for the concise, controlled description of environments
- National Center for Biotechnology Information (NCBI) Organismal Classification (NCBITAXON)
- The NCBI Taxonomy Database is a curated classification and nomenclature for all of the organisms in the public sequence databases.
- Information Artifact Ontology (IAO)
- this ontology contains terms related to information entities (eg: journals, articles, datasets, identifiers)
To search, navigate through the “classes” until you find an appropriate term. When we are picking terms, it is important that we don’t just pick a similar term or a term that seems close - we want a term that is 100% accurate. For example, if you have an attribute for carbon tetroxide flux and an ontology with a class hierarchy like this:
– carbon flux
|—- carbon dioxide flux
Our exact attribute, carbon tetroxide flux, is not listed. In this case, we should pick “carbon flux” as it’s completely correct/accurate and not “carbon dioxide flux” because it’s more specific/precise but not quite right.
For general attributes (such as ones named depth or length), it is important to be as specific as possible about what is being measured.
e.g. selecting the lake area annotation for the area attribute in this dataset
3. Build the annotation in R
4.7.2.1 Manually Annotating
This method is great for when you are inserting 1 annotation, fixing an existing annotation, or programmatically updating annotations for multiple attributeLists.
First, you need to figure out the index of the attribute you want to annotate.
[1] "prdM" "t090C" "t190C" "c0mS/cm" "c1mS/cm" "sal00" "sal11" "sbeox0V" "flECO-AFL"
[10] "CStarTr0" "cpar" "v0" "v4" "v6" "v7" "svCM" "altM" "depSM"
[19] "scan" "sbeox0ML/L" "sbeox0dOV/dT" "flag" Next, assign an id to the attribute. It should be unique within the document, and it’s nice if it is human readable and related to the attribute it is describing. One format you could use is entity_x_attribute_y which should be unique in scope, and is nice and descriptive.
Now, assign the propertyURI information. This will be the same for every annotation you build.
doc$dataset$dataTable[[3]]$attributeList$attribute[[6]]$annotation$propertyURI <- list(label = "contains measurements of type",
propertyURI = "http://ecoinformatics.org/oboe/oboe.1.2/oboe-core.owl#containsMeasurementsOfType")Finally, add the valueURI information from your search.
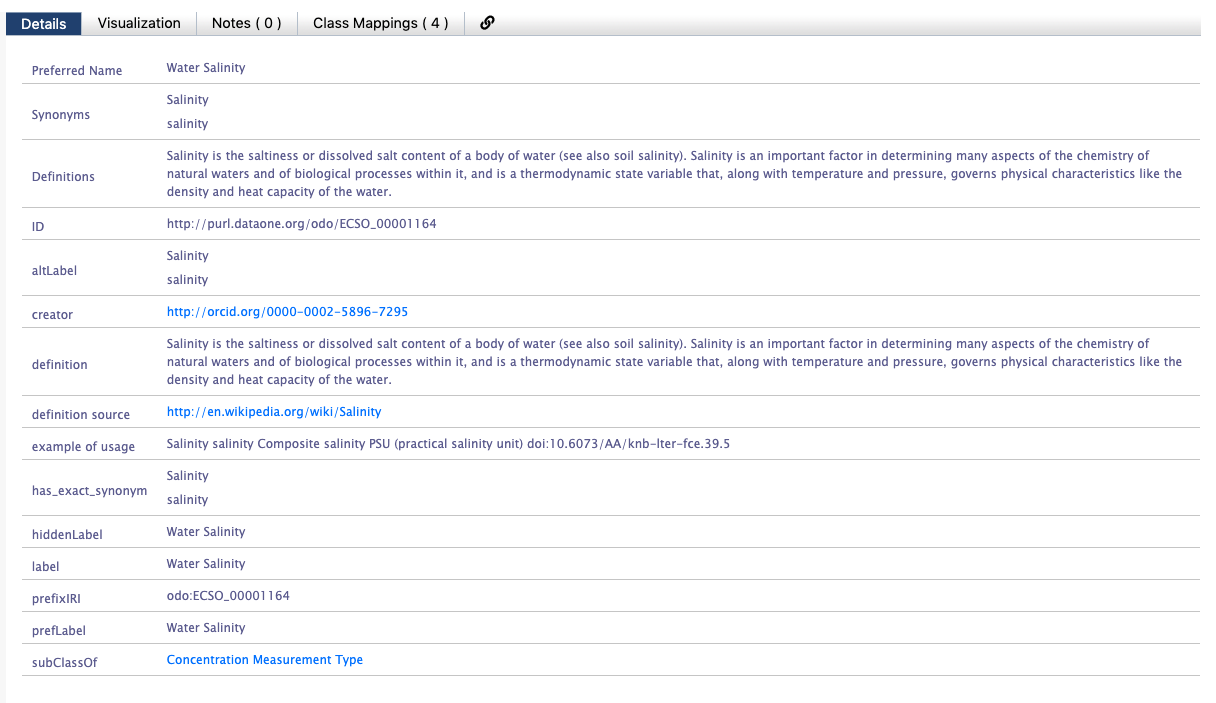 You should see an ID on the Bioportal page that looks like a URL - this is the
You should see an ID on the Bioportal page that looks like a URL - this is the valueURI. Use the value to populate the label element.
doc$dataset$dataTable[[3]]$attributeList$attribute[[6]]$annotation$valueURI <- list(label = "Water Salinity",
valueURI = "http://purl.dataone.org/odo/ECSO_00001164")If you are working to programmatically add annotations in, we recommend using dplyr or other data.table manipulation tools to build out/edit your attributeTable and then using set_attributes to assign it back to the EML document.
4.7.2.2 Shiny Attributes
This method is great for when you are updating many attributes.
You can use the shiny_attributes function to build out the attribute list and then use set_attributes to assign it to the EML document. This is a much more efficient way to add annotations to many attributes across many files.
On the far right of the table of shiny_attributes there are 4 columns: id, propertyURI, propertyLabel, valueURI, valueLabel that can be filled out.
4.7.2.3 External Editing
This method is great if you are more comfortable editing in Excel or Google Sheets, but it is not recommended for large datasets with many attributes.
Since an attributeTable is just a data frame, you can export it to a CSV, edit it in Excel or Google Sheets, and then read it back into R and assign it to the EML document. This is not recommended for large datasets with many attributes because it is easy to mess up the formatting of the attributeTable and lose information about the attributes that are not being edited.
4.7.3 Dataset-level Annotations
We also want to annotate datasets with information about the discipline of the dataset and the sensitivity of the data.
There are several helper functions that assist with making dataset annotations.
4.7.3.1 Data Sensitivity
Sensitive datasets that might cover protected characteristics (human subjects data, endangered species locations, etc) should be annotated using the data sensitivity ontology: https://bioportal.bioontology.org/ontologies/SENSO/?p=classes&conceptid=root. The sensitivity annotations can be added through the web editor, and it is a required section for submitters.
4.7.3.2 Dataset Discipline
As a final step in the data processing pipeline, we will categorize the dataset with a discipline. We are trying to categorize datasets so we can have a general idea of what kinds of data we have at the Arctic Data Center. It also helps with searching and filtering datasets on the website.
Datasets will be categorized using the Academic Ontology. These annotations will be seen at the top of the landing page, and can be thought of as “themes” for the dataset. In reality, they are dataset-level annotations.
Be sure to ask your peers in the #datateam Slack channel whether they agree with the themes you think best fit your dataset. Once there is consensus, use the following line of code:
Be careful not to duplicate dataset annotations. The above code does not remove existing dataset annotations. Duplicate annotations can be removed by setting them to NULL.
4.8 Set the project section
The project section in an EML document is automatically filled out by the metacatUI editor when a dataset is submitted. It sets the project title and project personnel to the submission’s title and creators. Most of the time, at least some of this information is incorrect and we need to update it.
If the dataset is funded by NSF, the project information can be found in the NSF award search. We’ve built a function in arcticdatautils that can help you retrieve this information and format it for EML in the award element. If your dataset is funded by another agency, you will need to find the custom project information and format it as an award element for EML yourself.
4.8.1 NSF Awards
There is a helper function eml_nsf_to_project() that can help find the necessary information for you. Just verify that the information retrieved is correct. This will create an award element in the project section, and it will remove the funding section.
# update NSF awards data
awards <- c("1311655", "1417987", "1417993") # list of award numbers
proj <- eml_nsf_to_project(awards) #helper function
doc$dataset$project <- projBefore this function, we would need to find the award information manually and format it for EML.
To do that, you would start by searching for the funding information using NSF’s award search. This will give us the project title, abstract, and personnel - along with some additional metadata.
Using this information we can set the title, personnel, and funding number. For NSF funded projects prepend the funding number with “NSF”. If there are multiple awards associated with one dataset then additional funding, title, and personnel elements should be added to reflect the additional awards.
doc$dataset$project$title[[1]] <- 'Collaborative Research: Reconciling conflicting Arctic temperature and fire reconstructions using multi-proxy records from lake sediments north of the Brooks Range, Alaska
doc$dataset$project$personnel[[1]] <- eml$personnel(individualName = eml$individualName(givenName = 'Yongsong', surName = 'Huang'),
role = 'Principal Investigator')
doc$dataset$project$personnel[[2]] <- eml$personnel(individualName = eml$individualName(givenName = 'James', surName = 'Russell'),
role = 'co Principal Investigator')4.8.2 Custom Awards
If there is a funding source that is not from NSF, we will need to create a custom award element. The required information for an award element is the funderName and title. The awardNumber and funderIdentifier are optional, but if you have that information it can be added as well.
Below is some example code for creating a custom award element.
### Add Awards Section
award_1 <- eml$award(funderName = "Programme for Monitoring of the Greenland ice sheet (PROMICE.org)",
title = "The SUMup collaborative database: Surface mass balance, subsurface temperature and density measurements from the Greenland and Antarctic ice sheets (1912 - 2023)"
)
doc$dataset$project$award <- award_1
doc$dataset$project$funding <- NULL # remove funding sectionproject$award$funderName # required
project$award$title # required
project$award$awardNumber
project$award$funderIdentifierInformation can be found in using the Open Funder Registry. If a award title cannot be found you can use the dataset title.
4.9 Exercise 3a
The metadata for the dataset created earlier in Exercise 2 was not very complete. Here we will add an attributeTable and physical to our entity (the csv file).
- Make sure your package from before is loaded into R.
- Convert
otherEntityintodataTable. - Replace the existing
dataTablewith a newdataTableobject with anattributelistyou write in R using the above commands. - Be sure to add attribute-level annotations when possible to the attributes.
- Add a physical to your entity using the
pid_to_eml_physicalfunction fromarcticdatautils. - Categorize the dataset by adding a dataset-level annotation with a discipline.
- Add the
awardsection given the funding information. - We will continue using the objects created and updated in this exercise in 3b.
Below is some pseudo-code for how to accomplish the above steps. Fill in the dots according to the above sections to complete the exercise.
# get the latest version of the resource map identifier from your dataset on the arctic data center
resource_map_pid <- ...
dp <- getDataPackage(d1c_test, identifier=resource_map_pid, lazyLoad=TRUE, quiet=FALSE)
# get metadata pid
metadataId <- selectMember(...)
# read in EML
doc <- read_eml(getObject(...))
# write an attribute list using shiny_attributes based on the data in your file
ex_data <- read.csv(...)
atts <- shiny_attributes(data = ex_data)
# set the attributeList
doc$dataset$otherEntity$attributeList <- set_attributes(...)
# convert otherEntity to dataTable
doc <- eml_otherEntity_to_dataTable(...)
# add physical
...
# add dataset-level annotation
# add award elements
# add publisher and entity information
4.10 Validate EML and update package
To make sure that your edited EML is valid against the EML schema, run eml_validate() on your EML. Fix any errors that you see.
You should see something like if everything passes: >[1] TRUE >attr(,“errors”) >character(0)
When troubleshooting EML errors, it is helpful to run
eml_validate() after every edit to the EML document in
order to pinpoint the problematic code.
Then, save your EML to a path of your choice or a temporary file. You will later pass this path as an argument to update the package.
4.11 Exercise 3b
- Make sure you have everything from before in R.
After adding more metadata, we want to publish the dataset onto test.arcticdata.io. Before we publish updates we need to do a couple checks before doing so.
- Validate your metadata using
eml_validate. - Use the checklist to review your submission.
- Make edits where necessary (e.g. physicals)
Once eml_validate returns TRUE go ahead and run write_eml, replaceMember, and uploadDataPackage. There might be a small lag for your changes to appear on the website. This part of the workflow will look roughly like this:
# validate and write the EML
eml_validate(...)
write_eml(...)
# replace the old metadata file with the new one in the local package
dp <- replaceMember(dp, metadataId, replacement = eml_path)
# upload the data package
packageId <- uploadDataPackage(...)